

7 best tools for tracking app user behavior

Software bugs. We all know them, and we all know they’re unavoidable.
Bugs are a natural part of the software development lifecycle, but dealing with them doesn’t have to be a long, drawn-out process.
If you’re looking for ways to resolve software bugs faster, you’re in the right place.
This article will explore six key practices that significantly improve debugging efficiency.
We’ll cover everything from effective bug management and prioritization to clear communication within your team and the benefits of automated testing.
Let’s get started.
Table of Contents
Efficient bug resolution starts with thorough testing.
The goal is to catch as many bugs as early as possible, avoiding the complexities and time-consuming fixes of finding them in a later development phase.
While manual testing has its place here, it can’t match the efficiency of automated testing, as you can see from the table below:
| Feature | Manual Testing | Automated Testing |
| Speed | Slower, repetitive tests take significant time | Much faster, especially for regression testing |
| Cost | Lower initial cost, higher long-term cost | Higher initial cost, lower long-term cost |
| Accuracy | Prone to human error | More accurate and consistent |
| Coverage | Limited by time and resources | Covers more scenarios, including edge cases |
| Maintenance | Less maintenance required for individual test cases | Requires ongoing maintenance of test scripts |
| Human element | Can identify usability and UX issues | Limited ability to assess user experience |
Given these advantages, it’s not surprising that many development teams use automation to optimize their testing efforts.
According to PractiTest, 75% of those surveyed saw at least some reduction in manual testing with automation.
And a fifth of them saw a major drop, with automation replacing over 75% of their manual testing work.

The same report points out that many teams use tools to optimize their automated testing further, with Jenkins being a popular choice.
Jenkins is an open-source automation server that streamlines software development by handling tasks like building, testing, and deploying.
It supports continuous integration and delivery, making development more efficient.
Plus, Jenkins can easily integrate with platforms like GitHub.
For example, if a developer commits code to a GitHub repository, this action can automatically trigger a build process in Jenkins.
Jenkins then pulls the latest code, compiles it, and runs the predefined automated tests.
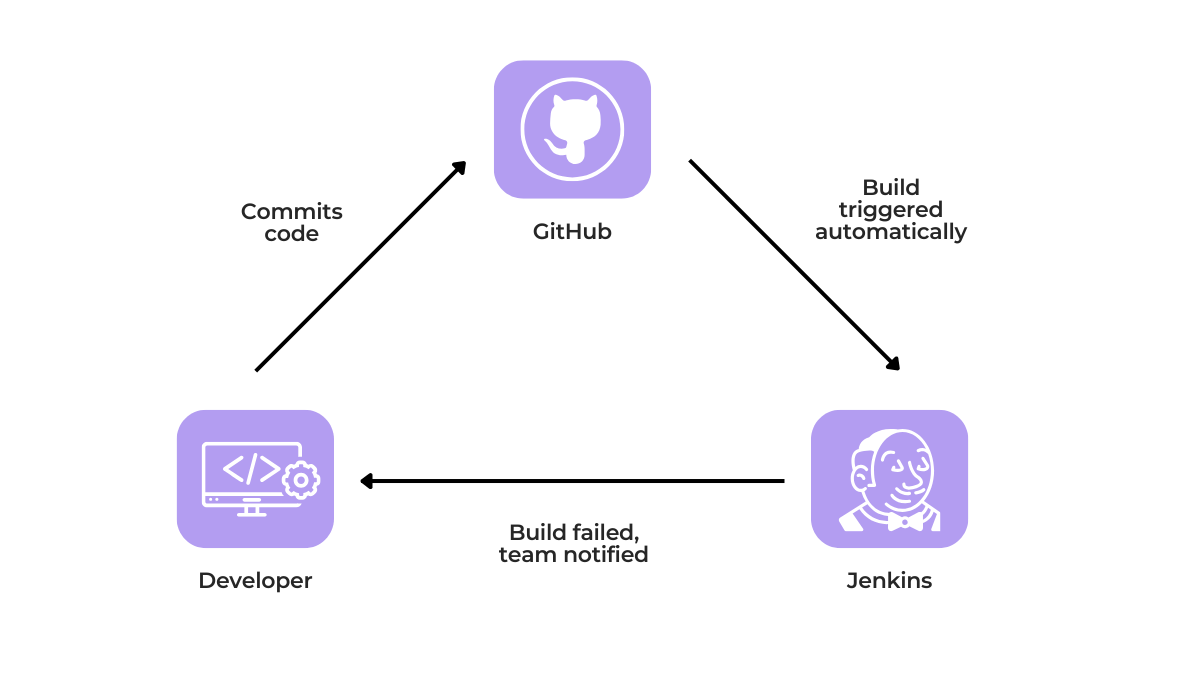
This tight integration allows for rapid feedback and helps identify and address issues very early in the development cycle.
Overall, by combining automated tests with tools to manage and run them, you can detect and fix bugs much faster.
Automated tests give you quick feedback, so developers can address issues quickly.
This frees up their time for more important tasks, like building new features and responding to user feedback.
When working with bugs, it’s only natural to mention bug reports.
The quality and depth of these reports directly impact how quickly bugs get fixed.
After all, a comprehensive bug report, with all the necessary information, gives testers and developers what they need to debug efficiently.

They can quickly reproduce the issue by following the steps provided and recreating the same device environment.
Plus, attached logs and technical data can help them pinpoint the root cause of the problem much quicker.
So, it’s that simple—each bug report needs to be clear and comprehensive.
Unfortunately, developers and testers don’t always adhere to reporting best practices, which sometimes results in incomplete reports.
Consider this experience shared by a software tester on Reddit:
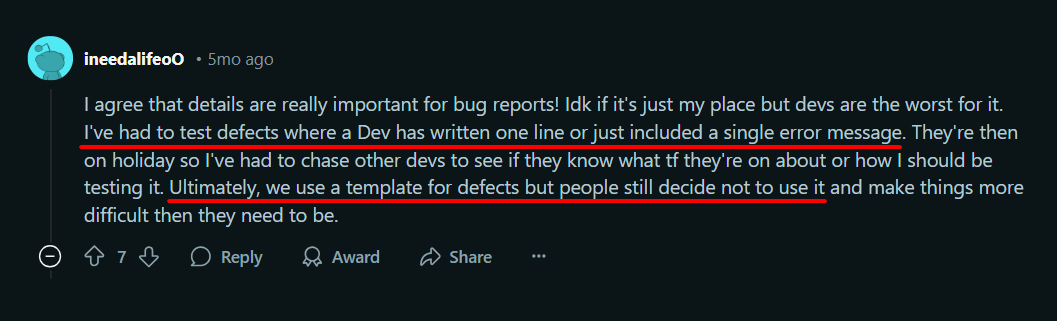
In this user’s case, even when bug reporting templates were implemented, they were useless as not everyone used them consistently.
So, how do we fix this?
Enforcing good reporting practices and highlighting their benefits is a good first step toward better bug reports and faster fixes.

Get unreal data to fix real issues in your app & web.
But what if that doesn’t work?
What if the bug report is sent by an end-user and missing key details?
A bug reporting tool like Shake offers a solution.
Shake allows for in-app bug reporting, so no one has to create reports manually.
When a user, tester, or developer encounters a problem, they just shake their device or tap a button to open a new ticket screen.
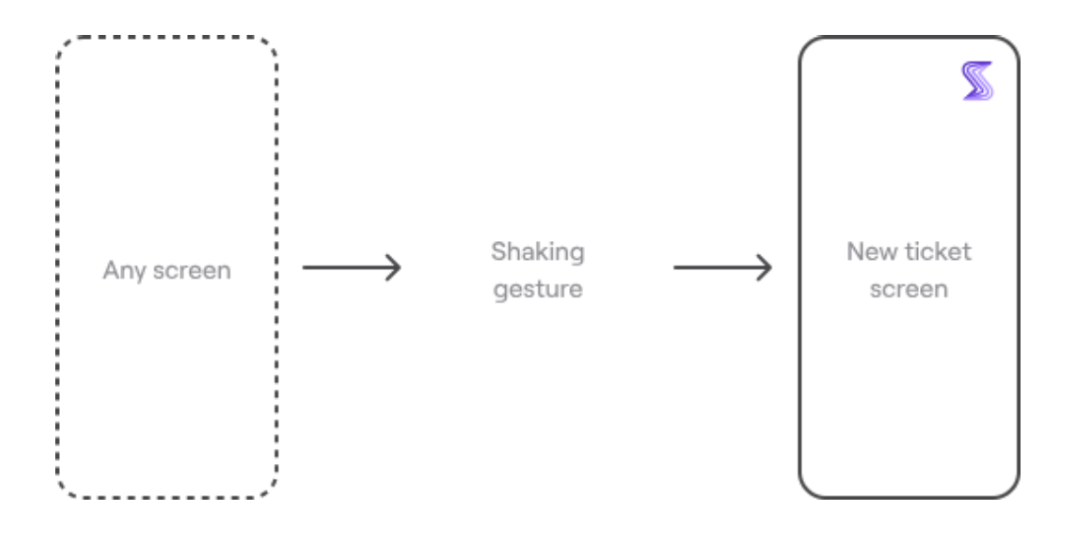
From there, they can create their bug report or feedback and submit it directly.
But the real magic happens behind the scenes, as Shake automatically collects and attaches over 70 data metrics to each report.
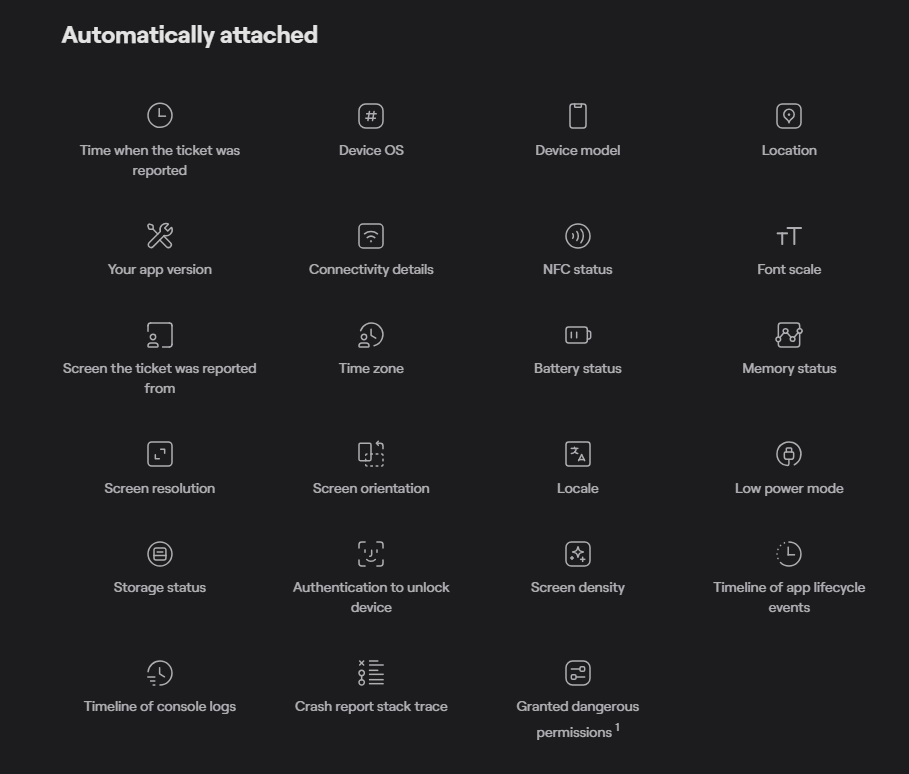
These metrics include key environment data, such as device OS and model, connectivity details, screen orientation, and more.
Automatic video recordings and screenshots can also be included, showing developers exactly what the user was doing before the bug occurred.
Ultimately, instead of bug reports coming in with various levels of detail, Shake can ensure each report is clear, and has all the necessary data to resolve bugs.
Once you receive a bug report, you need a solid process for managing and tracking it.
That’s why it’s good practice to establish a bug life cycle.
This is essentially a structured workflow that defines the different stages a bug goes through, from initial report to resolution.
One such lifecycle is shown in the image below.
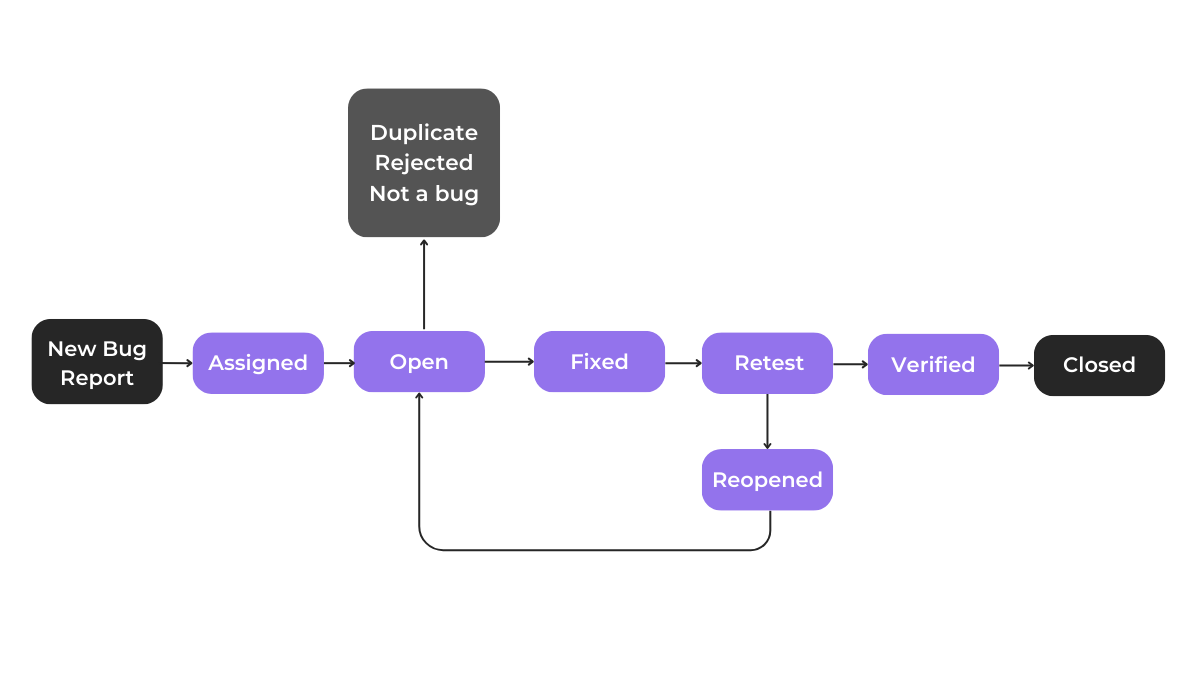
Without an efficient process and a structured tracking workflow, several problems can arise, hindering your bug resolution efforts.
For instance, duplicate bug reports can be mismanaged, leading to developers working on the same issue simultaneously, wasting valuable time and resources.
Even worse, bug reports can get lost or forgotten, allowing bugs to slip through the cracks and remain unresolved.
Fortunately, many systems out there can handle bug report management and tracking, including:
For example, Jira has various dashboards, such as the Kanban board, to visualize your bug management processes.
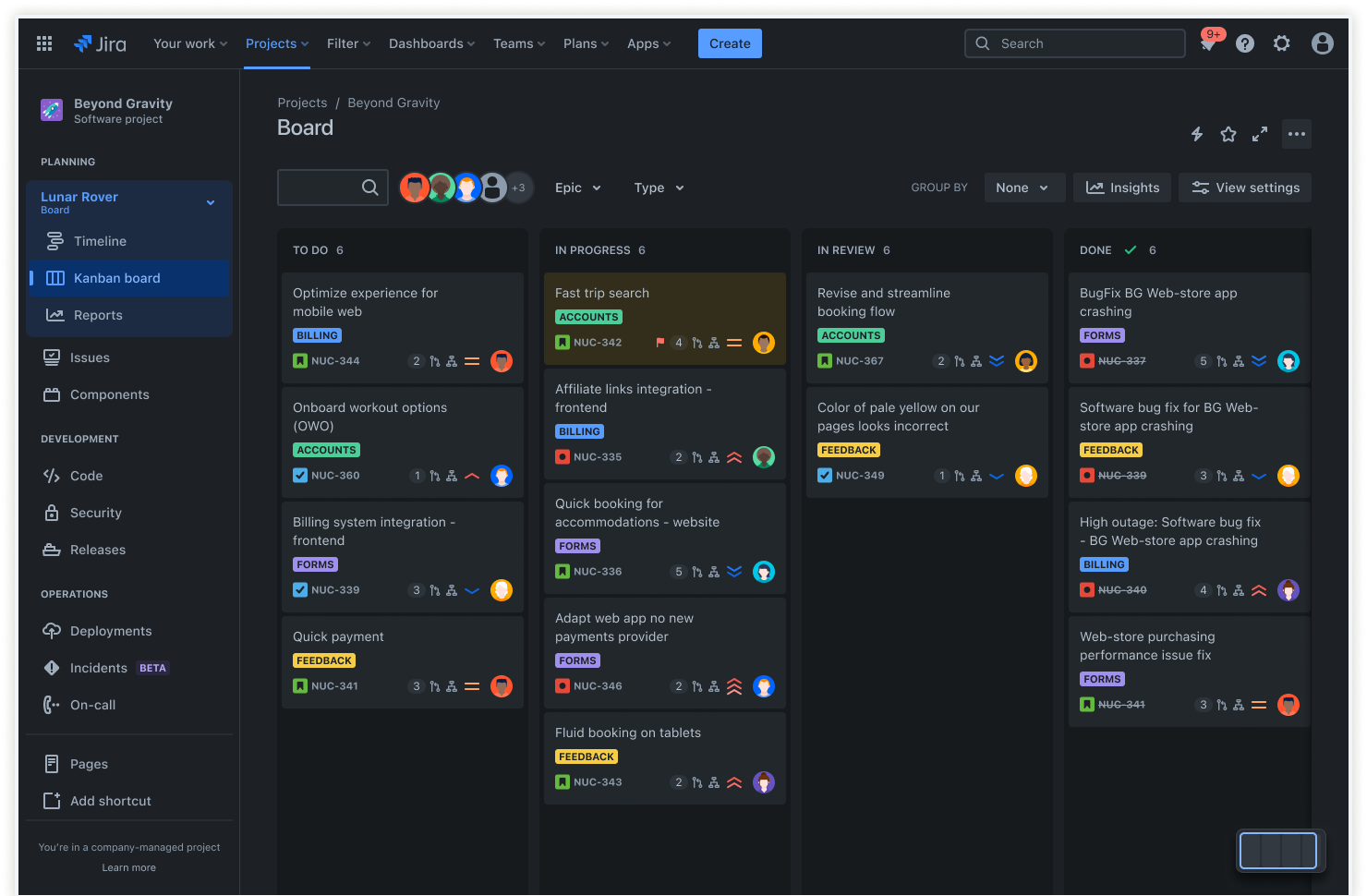
In fact, these boards can be customized to match any bug workflow your organization uses.
To streamline this process even further, you can use bug reporting tools that integrate with these project management and tracking systems.
For instance, Shake integrates with Jira, automatically sending bug reports directly to your Jira boards.
So, whenever someone reports a bug through Shake, the entire report will be created as a Jira ticket, with all fields mapped one-to-one and any screenshots and recordings automatically attached.
So, a structured bug life cycle, a centralized tracking system, and the right integrations can significantly improve your team’s ability to address and resolve issues faster.
Not all bugs are equal, and ranking them based on severity, frequency, and user impact helps teams focus on what matters most.
In other words, you have to establish bug priority.
The first step is to define the criteria you’ll use for prioritization, one of which is bug impact.
Take a look at the image below, showing some common bug impact levels.
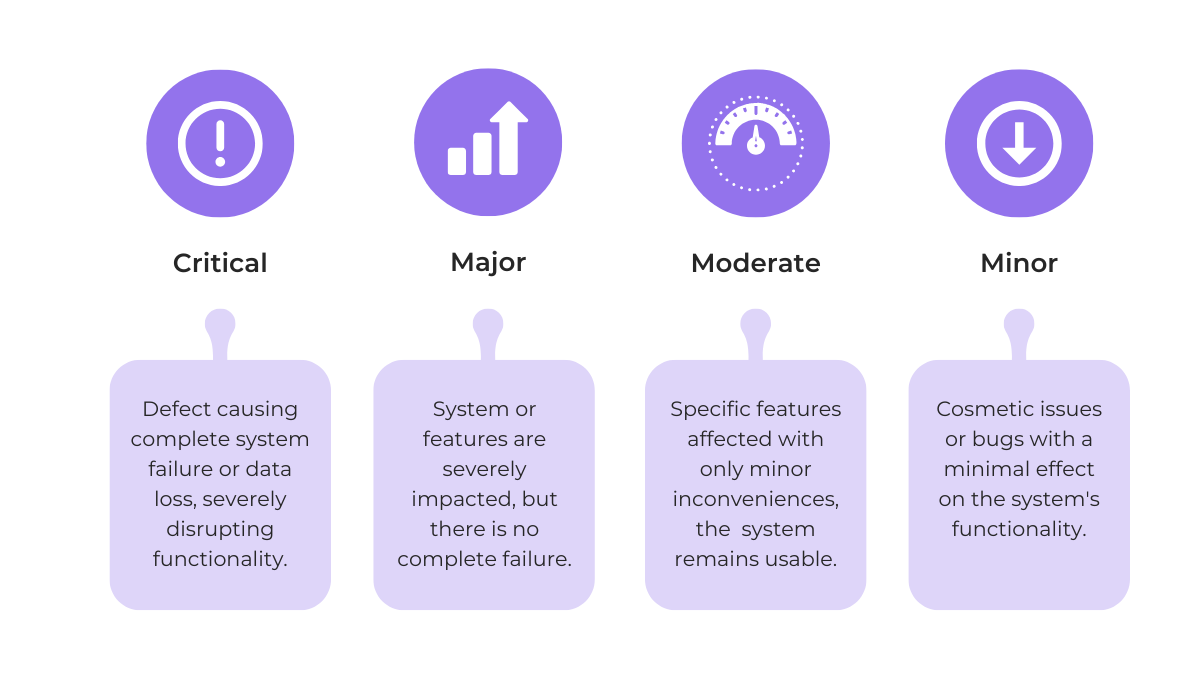
This categorization is useful because it helps you quickly identify and address bugs that severely damage the system.
Some other criteria for bug prioritization include:
| Frequency | How often does the bug occur? |
| Business impact | Does the bug affect revenue, customer satisfaction, or other key business metrics? |
| Users affected | How many users are impacted by the bug? |
Capture, Annotate & Share in Seconds with our Free Chrome Extension!
However, using these criteria in isolation isn’t very helpful.
That’s why you need to create priority categories that consider a combination of bug characteristics, and rank their importance accordingly.
A common practice is to use three priority levels: P0, P1, and P2.
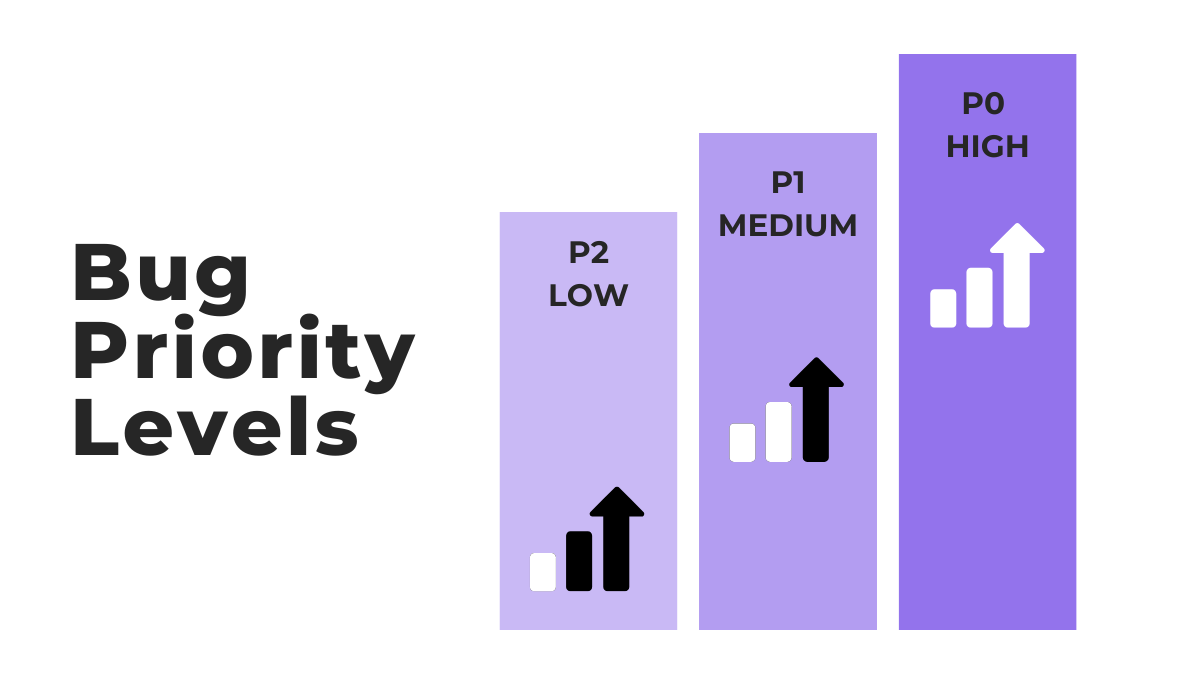
How you define these categories will depend on your specific priorities.
But, what’s important is that each category should trigger a specific action, whether it’s pooling all your resources to fix an issue immediately or postponing the fix.
For example, consider what Travis Kaufman, director of product marketing at Snowflake, and former software engineer, says about his experience with P0 bugs.
He further explains that P1 bugs were typically addressed in the next sprint, while P2 bugs were considered “nice to haves.”
Of course, while your own prioritization strategies may differ, having a clear system is crucial to ensure your team focuses on the most important bugs first.
Resolving issues effectively requires excellent team coordination and communication.
Clear communication, in this case, means that everyone is aware of the most critical bugs, their status, and who is responsible for fixing them.
Also, everyone should agree on what issues are a priority, which is well illustrated by the practice of bug triage.
A bug triage is a meeting where representatives from different teams discuss and prioritize reported bugs.
A typical bug triage meeting might include the following participants.
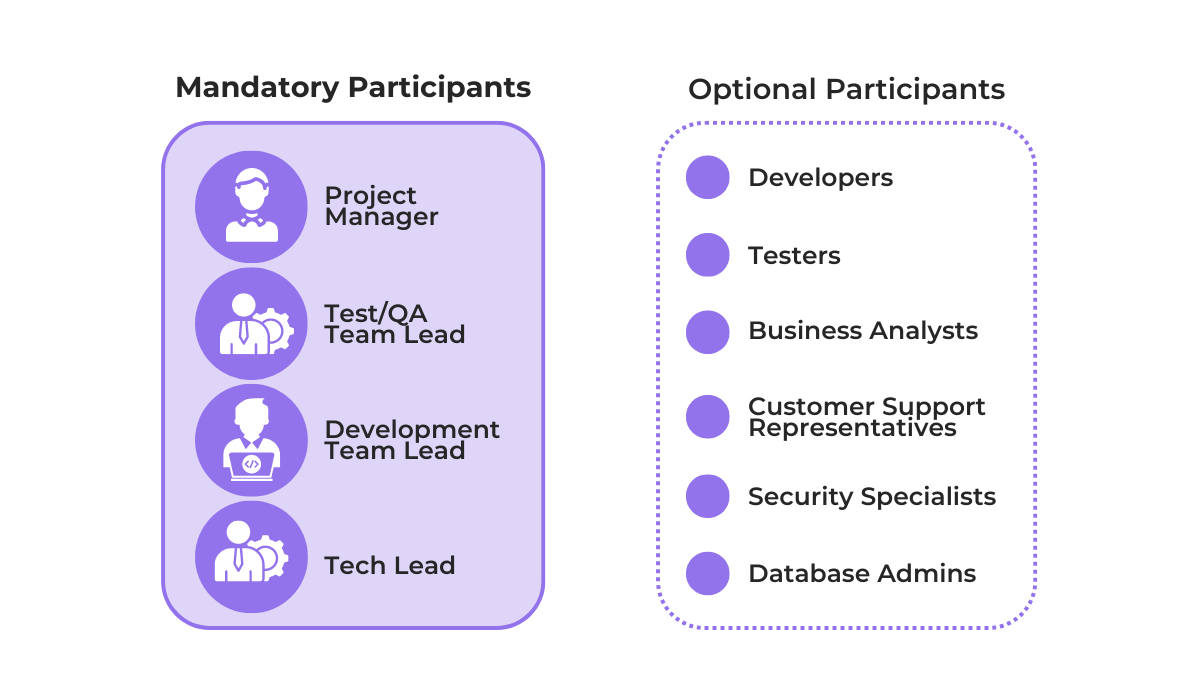
Bringing everyone together makes it easier to communicate clearly and stay on the same page about issues.
It also helps teams make quick decisions on which bugs to tackle first and who should handle them.
For even better cross-team communication, tools like Slack can be invaluable.
Slack is a collaboration platform that allows teams to communicate through channels, direct messages, and shared workspaces.
Plus, Slack’s powerful integrations with project management and bug tracking systems help connect all your workflows.
For example, Slack integrates with Jira, and tools like Jira are already great for collaboration.
They provide a centralized platform with high-level dashboards and insights into the bug management and tracking process.
But the collaboration gets even better with integrations.
For example, by mentioning an issue name or category in a Slack message, a Jira bot can immediately provide a basic summary of the issue.
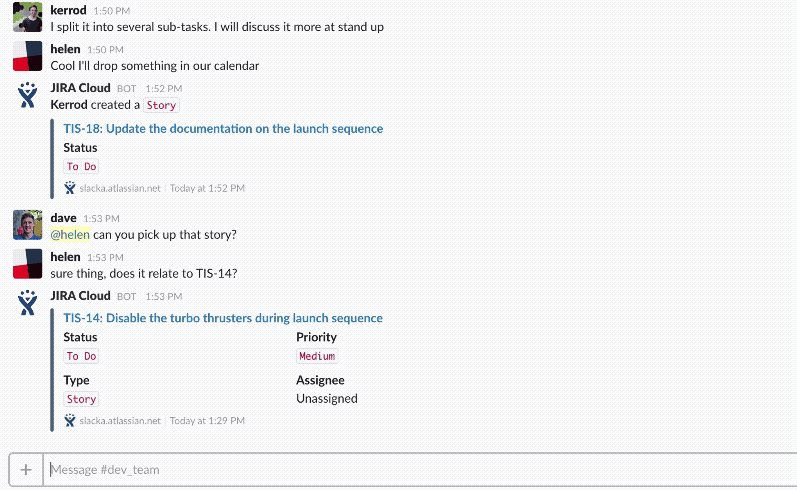
This removes the need to copy and paste links into another app, giving you context right within your ongoing conversation.
And all this is just scratching the surface of many other powerful integrations that facilitate collaboration.
The ultimate takeaway is that effective communication is essential for efficient bug resolution, no matter what tools or methods you use.
Just because a bug is resolved doesn’t mean the bug management process is over.
Issues can reoccur, closely related defects can arise, and developers can repeat the same mistakes.
That’s why it’s crucial to learn from errors.
A post-mortem is a retrospective process teams use to analyze what went well and what didn’t during an incident’s response and resolution.
As shown below, it should be conducted immediately after a bug is closed or an incident is resolved.
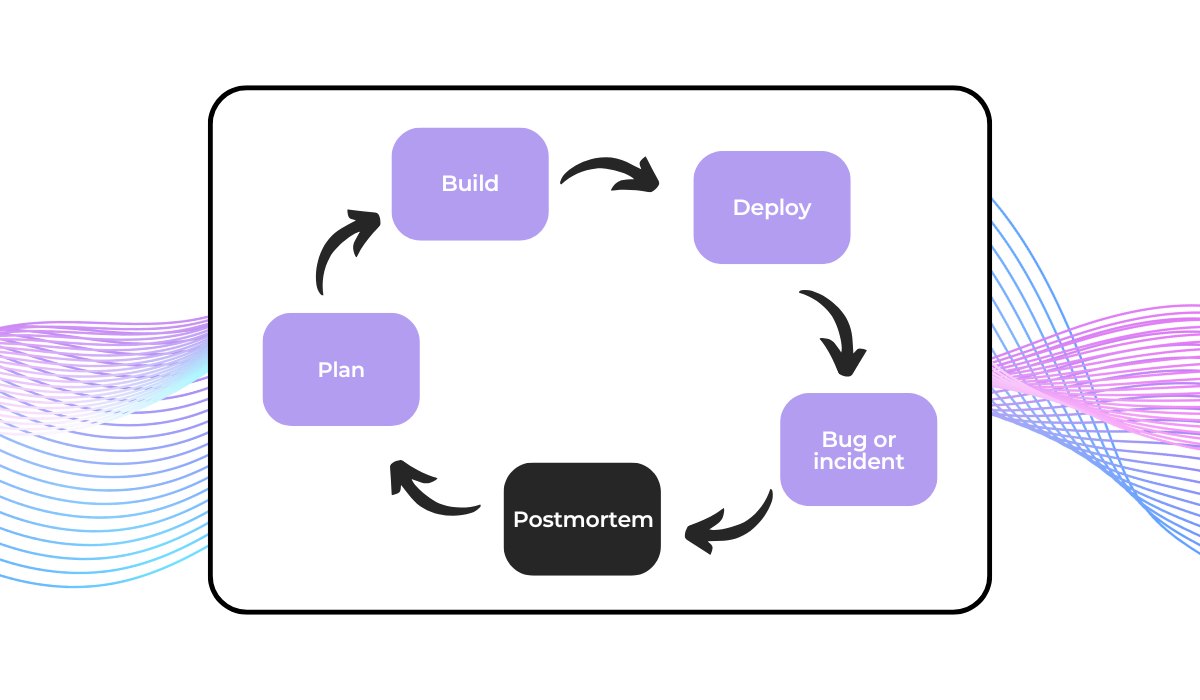
The insights gained from the post-mortem analysis should then be used to inform the planning of the next build and deployment cycle.
This might involve adjusting testing procedures, refining coding practices, or implementing new tools or processes to prevent similar issues from arising.
Usually, the post-mortem process involves creating incident reports, which should contain the following elements:
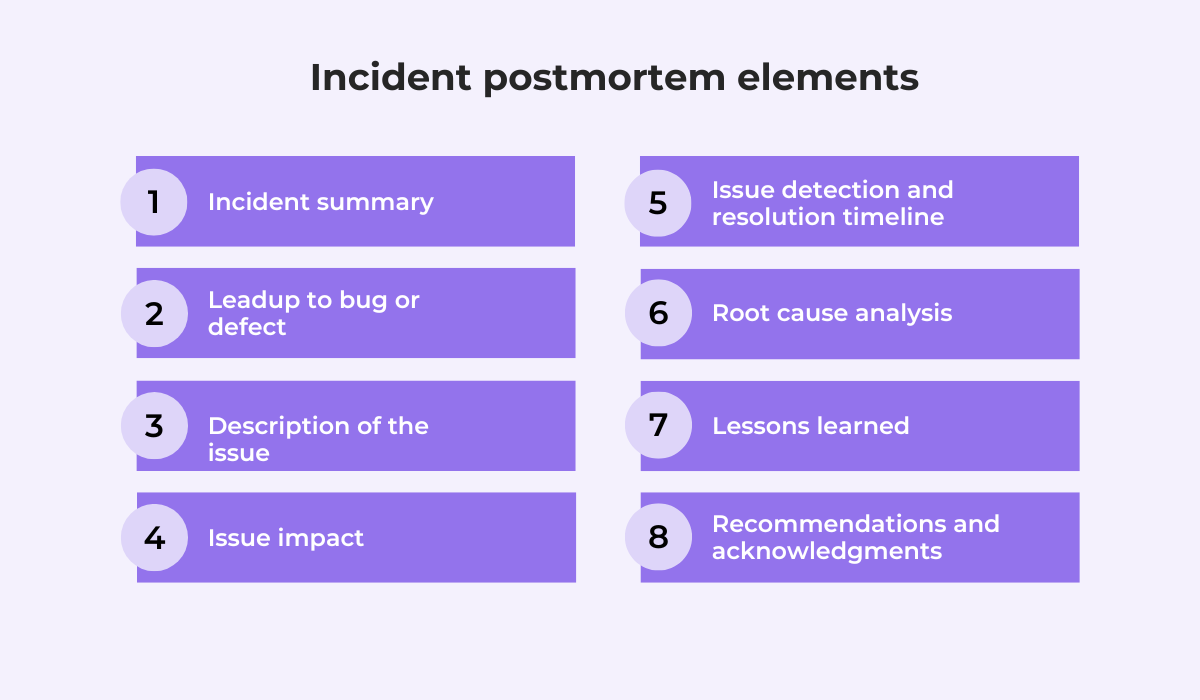
The first step is to thoroughly explain what happened, detailing its impact and the timeline of the response.
However, the most critical part is investigating the root cause of the issue.
Techniques like the “5 Whys” or fishbone diagrams can be helpful here.
Finally, to prevent recurrence, you need to document the lessons learned and formulate recommendations for the future.
These recommendations should be concrete and actionable, outlining specific steps that can be taken to avoid similar problems.
Some tools can streamline this post-mortem process.
For example, the New Relic platform offers a dedicated post-mortem feature designed to support a successful retrospective process.
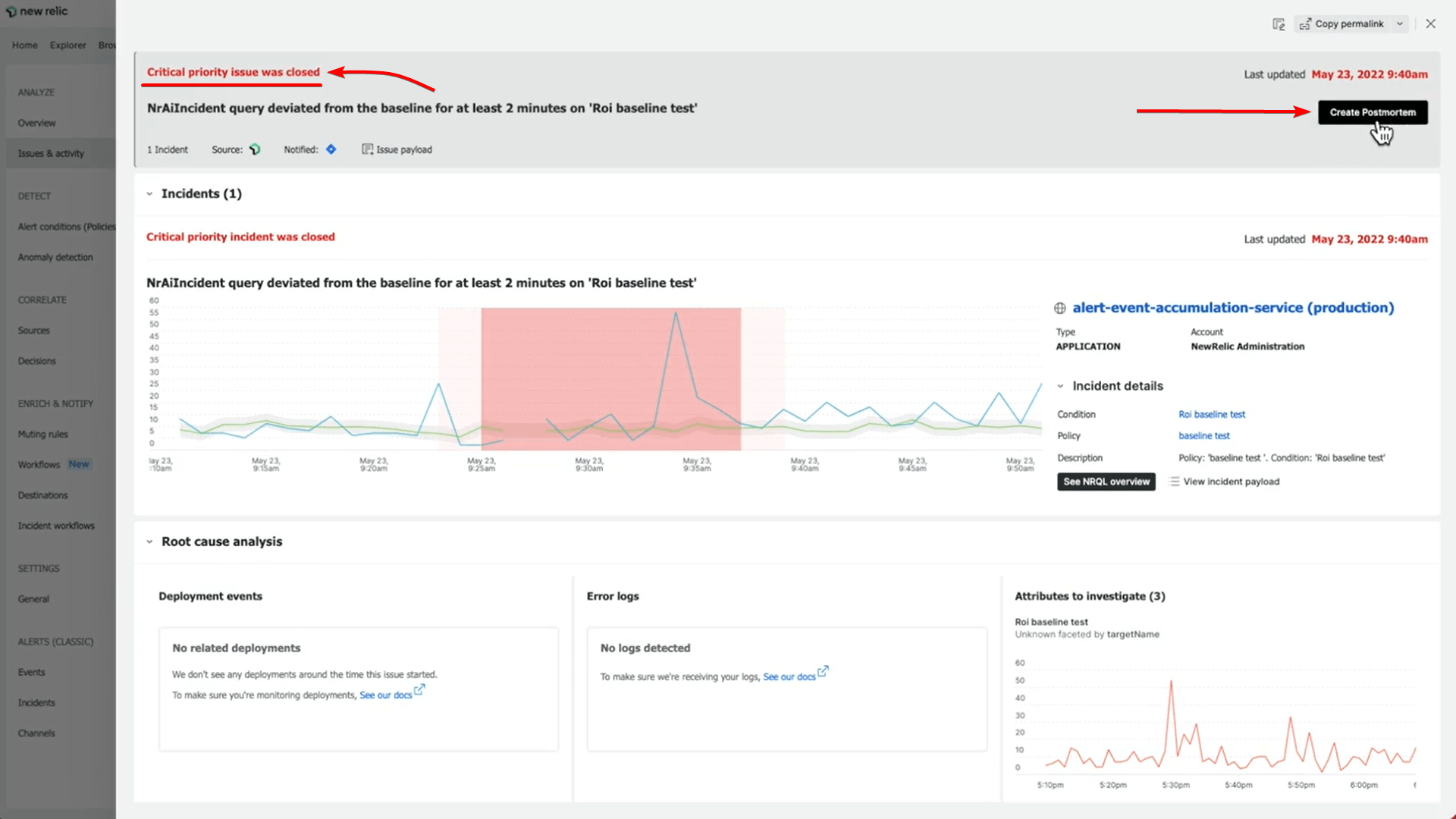
This feature helps collect all relevant data for the post-mortem analysis, including the incident timeline, impact, and mitigation measures taken.
It also provides a centralized location to store all your post-mortem analyses for future reference, creating a valuable knowledge base for the team.
In any case, whichever method or tool you use, post-mortem analysis is an essential preventive measure that helps teams learn from past issues and reduce the chances of similar problems in the future.
We’ve covered a lot of ground in this article, exploring some essential strategies for resolving software bugs faster.
From clear bug reporting to effective prioritization, automated testing, seamless team communication, and insightful post-mortem analysis—you’ve seen how these practices work together to transform your bug resolution process.
The big takeaway?
A systematic and proactive approach to bug resolution can dramatically reduce the time and effort required to fix issues.
Now, take these practices, apply them to your own workflow, and watch your debugging process level up.
From internal bug reporting to production and customer support, our all-in-one SDK gets you all the right clues to fix issues in your mobile app and website.
We love to think it makes CTOs life easier, QA tester’s reports better and dev’s coding faster. If you agree that user feedback is key – Shake is your door lock.
Read more about us here.

Add to app in minutes

Doesn’t affect app speed

GDPR & CCPA compliant

Unexpected things pop up
Just like bugs in your app or web 🐛 Fix them now with just one reporting tool.
